Here’s my complete playbook told the way I’d explain it to my own team when we’re mid-sprint, juggling releases, and still expected to “get automation done.”
We’re not starting on a clean slate. We’re stepping into a moving train: half-shipped features behind flags, staging that’s “almost prod,” OTP/2FA wired to real gateways, third-party widgets that blink, selectors that shift with every design tweak, and a release date nobody wants to slip. PMs want checkout automated “by Friday,” the CTO wants fewer production surprises, and QA is firefighting regressions while trying to prove automation is worth it.
In this reality, “automate everything” is a trap. What we actually need is a tiny set of always-green tests that protect the spine of the product and earn us time to expand. That’s the topic: choosing what to automate first so it helps the business today, stays stable tomorrow, and scales by Week 4.
Why talk about prioritization at all? Because automation only creates leverage when it guards what matters most and doesn’t flake. I’ve seen teams burn weeks automating low-value, high-drama flows personalized feeds, map tiles, animation-heavy carousels while login or checkout is still manual. Leadership doesn’t care about the number of tests; they care about fewer late-night rollbacks, faster merges, and reliable signals. A simple, shared scoring model gives us one language across PM, dev, and QA to pick the next right tes not by opinion, but by impact and feasibility. It lets us show value in Week 1 and compound it by Week 4.
Also Read: Why Microsoft Has 1 Tester Over 3 Developers
What Exactly are we Scoring?
Real, end-to-end flows a user takes: login with 2FA, signup and activation, UPI/subscription/checkout, create a core object (project/order/workspace), reset password, etc.
The scope is UI/E2E automation supported by API seeding, stable selectors (data-test-id), and, where sensible, contract tests and mocks for non-critical third parties.
The immediate outcome we want is small but powerful: three smoke flows that never blink, run on every PR and nightly, and prove that “green” means “ship.”
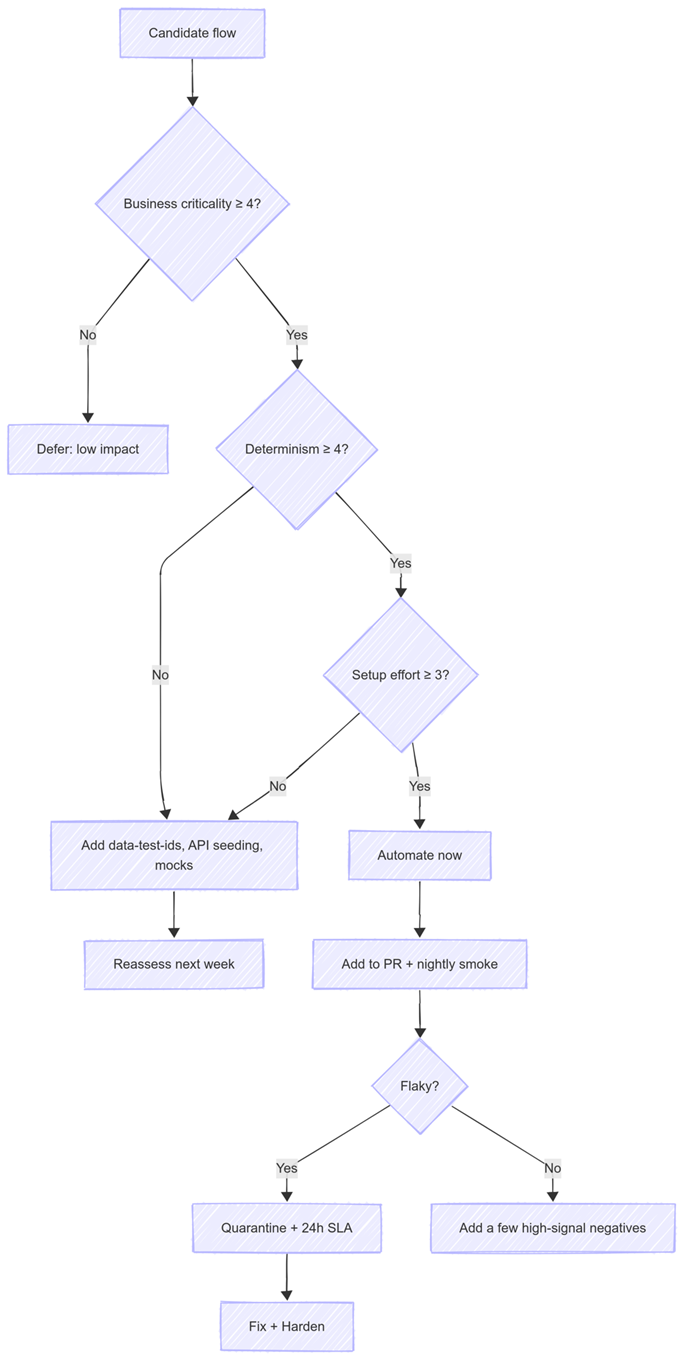
How do we Score without Ceremony? With Five Dimensions, each 1–5, where 5 means “great for early automation.”
- Business criticality (B): Does it touch revenue, activation, or retention? (1 = nice-to-have, 5 = P0 core journey)
- User frequency (F): How often real users hit it? (1 = monthly edge, 5 = daily)
- Failure impact (I): If it breaks, how bad? (1 = low severity, 5 = Sev-1)
- Determinism (D): Stable data, predictable UI, minimal randomness? (1 = highly flaky, 5 = very stable)
- Setup effort (S): Are we ready to automate? (1 = heavy manual seeding/stubs, 5 = API seeding + test IDs exist)
Two Formula Options Pick One and Stay Consistent:
- Equal weight (default): Total = B + F + I + D + S
- Early-stage bias (impact + stability): Total = 0.30B + 0.15F + 0.20I + 0.25D + 0.10S (weights sum to 1)
Also Read: Top 10 Accessibility Testing Tools
What does a first pass usually look like?
Advanced filters, invoice PDFs, and personalized carousels typically land mid-pack or lower because determinism and setup effort drag them down. If two flows tie, break ties with higher determinism and lower setup effort—stability buys speed.
So what ships first? Week 1 delivers three smoke flows:
- Authentication happy path (include 2FA if you use it).
- Activation/onboarding happy path (signup → verify → first-use milestone).
- Money or mission-critical moment (checkout/subscription/order, or create the core object).
After that, expand into deterministic, high-traffic journeys with clean test IDs and API factories.
What do we defer (for now)?
Low-determinism experiences (heavily personalized content, dynamic recommendations, time-window logic), brittle third-party widgets and map tiles, flows blocked by environment gaps (no API seeding, CSS-only selectors, live SMS/email without hooks), rare/low-impact admin pages, and purely visual animation-heavy UI—unless you already have robust visual baselines and tolerances. We revisit these once mocks/stubs, contract tests, feature flags, and stable selectors are ready.
How do we roll this out without derailing delivery? Think in weeks:
Week 0 – Enablement. Add data-test-id selectors. Expose idempotent API endpoints for seeding and cleanup. Decide environment rules (ephemeral data, fixed clock/time zone, feature flags). Define “green build” and create a quarantine lane for flakies.
Week 1 – Three smoke flows. Implement the top three end-to-end with API seeding. Run on every PR and nightly. Only these can fail the build. Capture videos, traces, and artifacts so triage takes minutes.
Week 2 – Expand + harden. Grow to 5–8 flows by pulling the next highest scores. Add one or two critical negative paths per flow (invalid payment, duplicate email). Tighten selectors, switch to event-driven waits, quarantine anything noisy, and set a 24-hour SLA to fix red tests.
Weeks 3–4 – Critical coverage. Reach 8–12 critical flows. Introduce contract tests/mocks for non-critical third parties. Add dashboards for pass rate, duration, and flaky rate. Track SLAs and keep the main branch boringly green.
How do we run the scoring workshop without turning it into a meeting festival? One PM, one developer, one tester per product area. Brain-dump flows into a shared doc with short, outcome-focused names. Score each flow in 3–5 minutes—don’t overthink. Sort by total, pick the top 3–5, lock Week 1–2 commitments. Re-score monthly or after major product changes. The ritual is light so we keep moving.
Also Read: API Automation Testing with Postman & Newman: From Setup to CI/CD Integration
How do we implement determinism instead of praying for it?
- Add stable selectors (data-test-id) and avoid dynamic XPaths or brittle CSS chains.
- Freeze time in tests; seed randomness with known seeds.
- Own your data lifecycle with API factories (create/read/update/delete) that are idempotent.
- Tame third parties—mock non-critical services in E2E and cover them with contract tests in isolation.
- Replace arbitrary sleeps with event-driven waits (UI signals, network idle, request/response hooks). This is the boring work that makes automation feel like a superpower later.
What metrics matter from day one?
- Pass rate of the smoke suite on main.
- Flaky rate per test and per component.
- Mean time to diagnose (MTTD) and fix (MTTR) red builds.
- Coverage of top critical flows against plan.
- Runtime and parallelization efficiency.
- If these trends are healthy, the rest of your strategy is probably healthy too.
What pitfalls do we actively avoid?
- Automating edge cases before happy paths.
- Letting one flaky test block all merges (quarantine fast, fix under SLA).
- Over-mocking core flows that should be truly end-to-end.
- Writing tests without stable data or selectors.
- Skipping negative paths forever-add a few high-signal negatives once your greens stay green.
Also Read: Why Product-Based Companies Should Rely on External QA Services Over Internal QA Teams
What does good look like in plain terms?
By the end of Week 1, three green, high-value flows are guarding your release, running on every PR.
By Weeks 3–4, you’re at eight–twelve critical journeys with stable selectors, API seeding, and a boringly green main branch. Red builds are diagnosed and fixed within 24 hours. Leadership sees fewer surprises; engineers merge faster; QA spends more time improving quality than repairing tests.
A quick weekly self-check keeps us honest: Do we have three smoke flows automated this week? Are our top flows actually the highest total scores? Do all automated flows use API seeding and test IDs? Are low-determinism flows explicitly deferred? Are we quarantining flakies and fixing them fast?
That’s the whole thing, end to end. Score 1–5 on criticality, frequency, impact, determinism, and setup effort. Sort by total. Automate from the top. Reassess weekly. Stability buys you speed; speed buys you trust—and trust is why automation exists in the first place.